





















Sep 13, 2016
Navigating the Population Health Storm – Is Big Data the Solution?

Written by Liam Bouchier
Category:
Data & Analytics

It has become clear in the past six years of the Affordable Care Act, which was introduced in March of 2010, that we are at a key pivoting point in healthcare.
Apart from the move from u2018fee for service’ to u2018value based’ payments, we are finally at a point to begin understanding how we can start to measure the quality of care being delivered via the availability of new and exciting data tools and technologies.
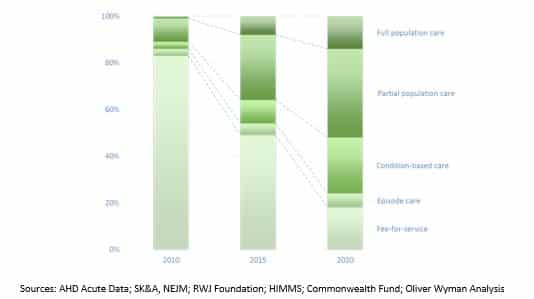
The concept of measurement of quality of care delivery has been embedded for decades in the UK and European countries primarily but not exclusively with single payer systems, allowing for large quantities of data to be gathered over time on how well care is being managed and delivered. As a result, many public health initiatives and interventions including longitudinal studies of disease and other epidemiology related research have been possible for a longer period of time and sometimes on a national scale.
More recently in the US market we have seen the buzzwords u2018Population Health’ and u2018Big Data’ become popular. Although not new, they are often spoken in the same sentence as a potential means of catching up to and even leapfrogging our European counterparts with regard to our analytical capabilities for the populations to whom care is being provided. In addition, and most significantly, there has been noticeable recognition by health systems and the supporting Health IT vendor community alike that the data elements required for the mounting reportable quality metrics from various Center for Medicare and Medicaid (CMS) initiatives as part of payment reform exist beyond hospital walls and beyond one single vendor solution. Meaningful use has certainly played a large part here in encouraging health systems to share data and will continue to do so, but a bigger population focus is needed.
Health systems that were pioneers in adopting the Primary Care Medical Home Model (PCMH), first championed by the National Committee for Quality Assurance (NCQA) with Federally Qualified Health Center Networks, are ahead of the curve in realizing that the primary care provider is really at the center of patient care beyond an acute episode. In the traditional Population Health Management approach, once a population is identified and defined, health assessments, risk stratification and management of that population quickly follow and the patients’ medical home primary care provider is best placed to coordinate this care. This approach allows for a comprehensive and coordinated longitudinal view of the patient care and history over time, but questions remain about how this solves the availability of data for reporting and analytics.
Can a big data solution help? The short answer is yes. Big data technologies are ideally suited to solving some of the challenges the healthcare industry have faced over the past several decades. The vast amount of data, both structured and unstructured, being generated on a day-to-day and minute-to-minute basis is a testament to this. Big data was originally conceived in 2005 in Silicon Valley, so the technology is hardly new but the application of it certainly has started to become an affordable reality with the decrease in storage cost and processing power. Cloud computing has played a large part in reducing the cost and more recently enterprise capable solutions are starting to emerge on the market as Health IT vendors take advantage of this technology in their solutions stack.

A key concept to keep in mind when deciding on a big data powered solution is that you don’t need to know what data problem you are trying to solve. Sound a little backwardu2026.it’s actually not!
The emphasis instead is on gathering data in multiple, ideally raw, formats from as many sources as possible to solve a question that later arises. That means you can include data from all types, formats and sources, structured or unstructured, to be later processed once a use case has been defined and the data is deemed useful to use. The enormous processing power of Big Data solutions allows for transformation of this data, in a batch or on the fly basis, to meet the use case you want to solve. You are not gathering data to insert into a predefined relational type structure, although if you would like to build that relational structure to support some dashboard reporting on the fly and have it update in real time, then yes, Big Data can do that, but think bigger!
Imagine a Health Level Seven (HL7) world where you don’t spend hours of an analyst’s time building interfaces, but rather you accept off the bat what a source system is capable of sending, the same in the claims world. Efficiencies in staff time alone are to be gained, not to mention the concept of enforcing data quality checks on large data sets for coding errors or claims files overnight before they go out the door for payment.
So does this technology solve the multiple data sources needed to report on the quality of care model? It’s a very large step in right direction and will allow health systems the flexibility to quickly take advantage of generating relevant analytics for the population they are serving at a community level, not just within hospital walls.
Headquarters
400 E. Diehl Road
Suite 190
Naperville, IL 60563
Downtown Chicago Office
980 N. Michigan Avenue
Suite 1998
Chicago, IL 60611
Phone
1-800-680-7570